Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Dateningenieur, AWS, Apache Airflow, Spark, PostgreSQL, ETL
Hast du Schwierigkeiten mit Rohdaten und keinen zuverlässigen Weg, sie zu verarbeiten?
Ich baue produktionsreife Datenpipelines, die automatisch laufen, mit deinen Daten skalieren und niemals still und heimlich versagen. Keine spaghettiartigen Skripte. Keine manuellen Schritte. Einfach saubere, zuverlässige Daten genau dort, wo du sie brauchst.
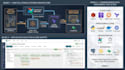
Was ich baue

Automatische Übersetzung
F: Welche Informationen benötigen Sie, um loszulegen?
A: Deine Datenquelle (S3, API, Datenbank, CSV), dein Zielort, Transformationsanforderungen und wie oft die Pipeline laufen soll.
Q: Kannst du mit meiner bestehenden Infrastruktur arbeiten?
A: Ja. Schick mir die Details und ich prüfe die Kompatibilität, bevor wir starten.
F: Brauche ich ein AWS-Konto?
A: Für AWS-basierte Arbeiten ja — du brauchst dein eigenes Konto. Ich kann dich bei der Einrichtung unterstützen, falls nötig.
F: Werde ich den Code besitzen?
A: Absolut. Der gesamte Quellcode wird dir bei Lieferung übergeben.
F: Können Sie mit großen Datenmengen umgehen?
A: Ja. Ich nutze PySpark und EMR auf EKS, weil sie speziell für groß angelegte Datenverarbeitung entwickelt wurden.
Q: Was, wenn nach der Lieferung etwas kaputt geht?
A: Ich biete Support nach der Lieferung an. Schreib mir und ich werde es beheben.


