Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Automatisierung, Web Scraping Django, Flask, Webentwicklung Frontend InstagramAnalyst
Level 1
Hat bestimmte Leistungskriterien erfüllt und zeigt großes Potenzial auf dem Marktplatz.
Hi,
Willst du Website-Daten schnell und sauber extrahieren? Ich erstelle maßgeschneiderte Python Web Scraper mit BeautifulSoup, Selenium, Playwright und Scrapy für präzise, automatisierte Datenextraktion von jeder öffentlichen Website.
Ich biete Experten-Level Python Web Scraping und Data Extraction Services mit branchenüblichen Tools wie:
️ Tools, die ich verwende:
Features & Output:
Ich scrape nur legal zugängliche und öffentliche Datenquellen.
Schreib mir vor der Bestellung, um deinen Anwendungsfall zu besprechen. Ich bin bereit, dir bei der Automatisierung und Datenextraktion zu helfen.
almohid

Automatische Übersetzung
Was ist Web-Scraping und wie kann es meinem Unternehmen nützen?
Web Scraping ist die automatisierte Extraktion von Daten aus Websites. Es ermöglicht Unternehmen, wertvolle, strukturierte Daten für Marktforschung, Wettbewerberanalyse, Preisüberwachung, Lead-Generierung, Produktdatenaggregation und Trendverfolgung zu sammeln – alles ohne manuellen Aufwand.
Welche Arten von Websites kannst du mit Python scrapen?
Ich scrape eine Vielzahl von Websites, darunter E-Commerce-Shops, Jobportale, Immobilienanzeigen, lokale Branchenverzeichnisse, Nachrichtenportale, akademische Datenbanken und mehr. *Hinweis: Überprüfe immer die Erlaubnis der Seite, bevor du scrapest.
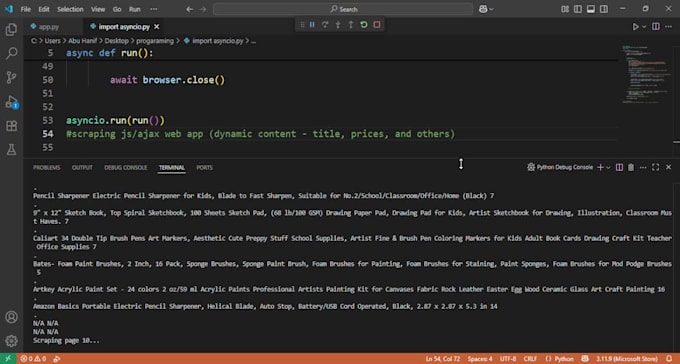
Kannst du Websites scrapen, die heavy JavaScript oder dynamisches Laden verwenden?
Absolut! Mit Playwright und Selenium bewältige ich komplexe Webseiten mit dynamischem Inhalt, der via AJAX, unendlichem Scrollen oder anderen JavaScript-gesteuerten Elementen geladen wird, sodass keine Daten verloren gehen.
Wie gehst du mit Websites um, die Login oder Session-Authentifizierung erfordern?
Ich automatisiere sichere Login-Prozesse mit Playwright oder Selenium, verwalte Cookies und Session-Tokens, um Daten hinter Login-Wänden zu extrahieren – vollständig konform mit den Nutzungsbedingungen der Website.
In welchen Datenformaten kann ich meine gescrapten Daten erhalten?
Ich liefere saubere, validierte Daten in Formaten wie CSV, Excel, JSON, XML, SQL-Datenbanken oder Google Sheets, angepasst an deinen Workflow oder deine Systemintegrationsbedürfnisse.
Stellst du die Scraping-Skripte und Automatisierungscodes bereit?
Ja! Auf Wunsch teile ich vollständig kommentierte, wiederverwendbare Python-Skripte, die mit Playwright, Selenium oder Scrapy erstellt wurden, damit du den Scraper eigenständig ausführen oder anpassen kannst.
Kannst du geplante und automatisierte Scraping-Jobs einrichten?
Definitiv. Ich konfiguriere Cron-Jobs, Cloud-Funktionen oder serverlose Scraper, die automatisch in benutzerdefinierten Intervallen laufen – täglich, wöchentlich oder monatlich – für eine kontinuierliche Datenaktualisierung.
Wie gehst du mit Anti-Scraping-Schutzmaßnahmen und Bot-Erkennung um?
Ich setze fortschrittliche Techniken ein, darunter User-Agent-Rotation, Proxy-Nutzung, Stealth-Browser-Modi (insbesondere mit Playwright), Request-Throttling und CAPTCHA-Handling (wo erlaubt), um gängige Anti-Bot-Maßnahmen ethisch zu umgehen.
Wie schnell kann ich mit meinen gescrapten Daten rechnen?
Die Dauer hängt von der Komplexität ab: einfache Scraping-Aufgaben dauern in der Regel 1-3 Tage; Multi-Page- oder groß angelegte Crawling-Projekte 3-7 Tage. Ich gebe vor Beginn klare, transparente Zeitpläne an.