Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Bangladesch
Über mich
Willst du ein selbstüberwachtes Lernmodell (SSL) erstellen und bedeutungsvolle Cluster in deinen Daten entdecken?
- Du bist hier genau richtig! Ich bin ein Deep Learning Experte mit praktischer Erfahrung in SSL, Clustering und Bewertung von Downstream-Aufgaben.
Ich kann mit verschiedenen Bilddatensätzen arbeiten, darunter:
Warum meinen Service wählen?
Was ich liefere:
Lass uns deine Daten zum Leben erwecken! Kontaktiere mich vor der Bestellung, um sicherzustellen, dass deine Projektanforderungen vollständig verstanden werden.



Expertise:
Bildverarbeitung
•
Klassifizierung
•
Clustering
Programmiersprache:
Python
•
Colab
•
Andere
Tools:
Jupyter-Notizbuch
•
opencv
•
Colab
•
PyTorch
Frameworks:
PyTorch
•
Panda
•
Andere
Automatische Übersetzung
Mit welchen Datensätzen kannst du arbeiten?
Ich kann mit jedem Bilddatensatz arbeiten, einschließlich medizinischer Bilder, Satellitenbilder, Produktbilder oder persönlicher/benutzerdefinierter Datensätze.
Muss ich einen Datensatz bereitstellen?
Ja. Wenn du möchtest, dass das Modell auf deinen Daten (Produkte, Gesichter, Dokumente usw.) trainiert wird, musst du die Bilder bereitstellen. Falls du keinen Datensatz hast, kann ich dir gegen eine zusätzliche Gebühr beim Sammeln oder Beschaffen eines Datensatzes helfen. Schreib mir zuerst eine Nachricht!
Brauche ich gelabelte Daten?
Nein, selbstüberwachtes Lernen benötigt keine gelabelten Daten. Labels können jedoch erforderlich sein, wenn du eine Bewertung bei einer Downstream-Aufgabe durchführen möchtest (Standard- & Premium-Pakete).
Gibt es Einschränkungen bei der Datensatzgröße?
Ich arbeite meist mit Datensätzen, die in den verfügbaren GPU-Speicher passen, zum Beispiel Colab und Kaggle GPU. Für sehr große Datensätze können wir Strategien wie Sampling, Batching oder verteilte Verarbeitung nutzen.
Welche Deep-Learning-Modelle verwendest du?
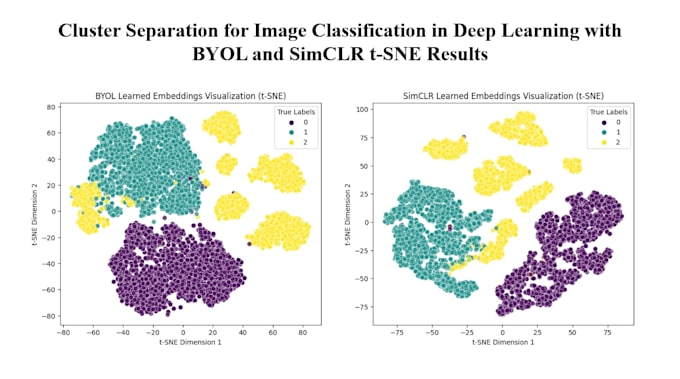
Ich verwende modernste selbstüberwachte Lernmodelle wie SimCLR, BYOL, Barlow Twins.
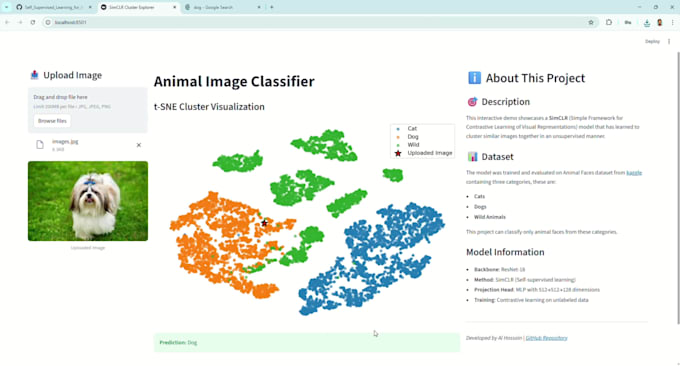
Werde ich das Modell einfach nutzen können?
Ja! Für das Premium-Paket stelle ich eine benutzerfreundliche Streamlit Web App bereit, um Cluster interaktiv zu erkunden und Downstream-Aufgaben zu testen.
Kannst du die Leistung des Modells bewerten?
Ja, ich liefere detaillierte Bewertungsmetriken für Downstream-Aufgaben, einschließlich Genauigkeit, Verlust und Visualisierungen der Cluster.
Sorgen Sie für Vertraulichkeit?
Ja, absolut. Deine Daten und Projektdetails bleiben streng vertraulich.