Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Data Analyst, Cloud Data Engineer and Data Warehouse Expert
Level 1
Hat bestimmte Leistungskriterien erfüllt und zeigt großes Potenzial auf dem Marktplatz.
Finding a reliable data pipeline solution that keeps analytics fresh and accurate?
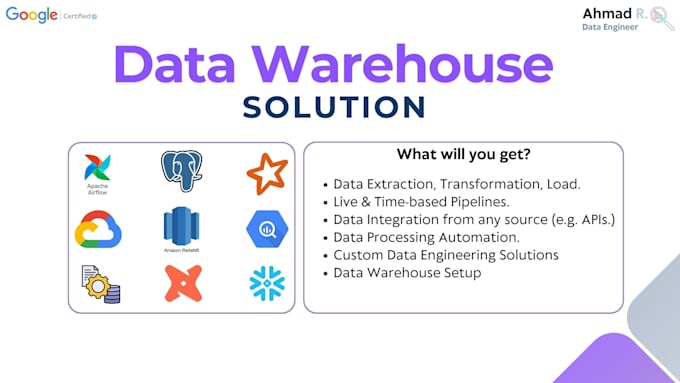
I will implement modern data engineering pipelines & data warehouses on Redshift, Google BigQuery, ClickHouse and Postgres.
Batch ETL/ELT pipelines and real-time streaming architectures, ensuring reliable, automated, and scalable data flows for analytics, and AI/LLM models.
What you get:
My Stack:
Why me:
Data Engineer with 7+ years of experience. I specialize in Redshift, Bigquery, PostgreSQL and custom data warehouse architectures.


What’s the difference between ETL and ELT pipelines?
ETL extracts, transforms, then loads data; ELT loads raw data then transforms it in the warehouse (common in BigQuery). We can implement either based on your needs.
Which warehouse is best for me?
Redshift works best for large AWS analytics workloads. BigQuery is a fully serverless GCP warehouse for fast, scalable queries. PostgreSQL is great for moderate data and complex SQL. ClickHouse excels at high-speed OLAP and real-time analytics. Choice depends on your data scale and use case.
Can you handle streaming data?
Yes – I build real-time pipelines using Kafka, Kinesis or GCP Pub/Sub. Streaming ETL is included in Premium package for up-to-date data flows.
What do you need from me to get started?
Please provide details of your data sources (type, access), desired warehouse, sample data/schema, and project goals (reports, ML use). This helps tailor the solution.
How do you use AI in the pipeline?
I use AI tools to automate parts of the workflow – for instance, using GPT to draft transformation code or infer data schema, and applying BigQuery ML/Redshift ML models via SQL for predictive features (where relevant).