Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
AI-Automatisierungsingenieur
Level 1
Hat bestimmte Leistungskriterien erfüllt und zeigt großes Potenzial auf dem Marktplatz.
Schnelle Antwortzeit
Zeichnet sich durch besonders schnelle Antwortzeit aus.
Immer noch manuell Rechnungs- oder PDF-Daten in Excel kopieren?
Ich helfe Unternehmen, die Datenextraktion aus Rechnungen und Dokumenten mit Python, OCR und individuellen Automatisierungs-Workflows zu automatisieren, um Stunden repetitiver Arbeit zu sparen.
Egal, ob du Daten aus Rechnungen, Quittungen, Berichten, gescannten PDFs oder Geschäftsdokumenten brauchst – ich kann unordentliche Dateien in saubere, strukturierte Excel-, CSV- oder JSON-Ausgaben umwandeln.
Was ich extrahiere:
So funktioniert es:
Ausgabeformate: Excel, CSV, JSON
Warum du mich wählen solltest:
Bist du bereit, manuelle Dateneingabe zu beenden? Schick mir deine Anforderungen und ich sende dir innerhalb einer Stunde ein individuelles Angebot.


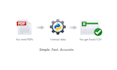

Technologie:
Excel
•
Python
•
Andere
Expertise:
Datenextraktion
•
Datenmanipulation
•
etl
•
Transformation
Automatische Übersetzung
Welche Arten von PDFs kannst du verarbeiten?
Jede PDF mit Text – Rechnungen, Kontoauszüge, Berichte, Verträge, Formulare oder gescannte Dokumente (OCR). Wenn du die Daten sehen kannst, kann ich sie extrahieren. Schick mir eine Probe, ich bestätige innerhalb einer Stunde.
Meine PDFs sind gescannte Bilder, kannst du trotzdem Daten extrahieren?
Ja. Ich nutze OCR (Optical Character Recognition), um Text aus gescannten PDFs, Fotos oder bildbasierten Dokumenten zu lesen. Das Premium-Paket beinhaltet vollständige OCR-Einrichtung. Das Standard-Paket funktioniert für digitale/Text-basierte PDFs.
Wie genau sind die extrahierten Daten?
Über 99 % Genauigkeit bei sauberen digitalen PDFs. Bei gescannten Dokumenten hängt die Genauigkeit von der Bildqualität ab. Ich überprüfe immer eine Probe vor der vollständigen Verarbeitung und füge einen Review-Schritt ein. Du genehmigst vor der finalen Lieferung.
Was passiert, wenn ich nach der Lieferung Änderungen benötige?
Jedes Paket beinhaltet Revisionen (1 Basic, 2 Standard, 3 Premium). Kleine Formatierungsänderungen sind kostenlos. Wenn du andere Felder extrahieren oder neue PDFs brauchst, ist das eine neue Bestellung, aber ich biete Rabatte für Stammkunden. Schreib mir einfach.


