Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
I build AI systems that run your business operations
Level 2
Hat hohe Leistungskriterien erfüllt und verfügt über eine nachgewiesene Erfolgsbilanz bei der Erfüllung von Kundenerwartungen.
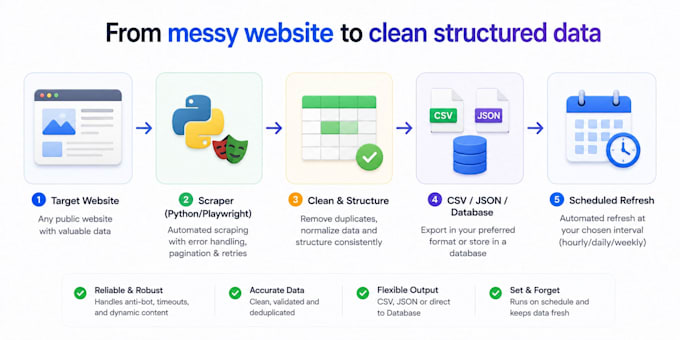
Need data from a website but copying it by hand is killing your time? I build Python scrapers and browser automation bots that pull clean, structured data on autopilot.
What I build:
Tools: Python, Scrapy, BeautifulSoup, Playwright, Selenium, Requests, curl_cffi, Pandas, proxy services (Bright Data, ScraperAPI, ZenRows).
I deliver ready to run code with clear instructions, so you can rerun it yourself anytime, plus 7 days of free fixes.
Message me with the target site and the fields you need.

Technologie:
Python
•
scrapy
•
Selen
•
Beautiful Soup
•
Dramatiker
Technik:
Automatisiert
Is this legal / compliant?
I follow website ToS, robots.txt, and privacy laws. I don’t collect sensitive personal data or bypass paywalls. Public/business data only.
Can you handle dynamic sites, infinite scroll, or JS rendered pages?
Yes using Playwright/Selenium/Scrapy with pagination, scrolling, wait conditions, and resilience against layout changes.
What do you need to start?
Website URL(s), fields to extract, sample page(s), expected volume, output format (CSV/Excel/JSON/Sheets/DB), and any login/test credentials if required.
What about captchas, rate limits, or blocks?
I use rotating proxies, user-agents, backoff/retries, and smart throttling. If heavy anti-bot is present, I’ll propose safe alternatives or partial coverage.
What formats can you deliver?
CSV, Excel, JSON, Google Sheets, or direct load to SQLite/PostgreSQL/MySQL. I can also provide a simple ETL-ready schema.
Do you include data cleaning and validation?
Yes, deduplication, trimming, type casting, regex parsing, and sanity checks for completeness/uniqueness where applicable.
Will I get the scraping script or only the data?
Basic/Standard deliver data. Premium includes Python code + setup guide. Script ownership transfers to you.
Can you set up scheduled scraping / monitoring?
Yes daily/weekly runs with email/Sheets updates. Premium can include Dockerized deployment or a lightweight cloud scheduler.
Can you scrape any website I want?
I can scrape most publicly accessible websites. Some sites have strict terms of service or require login to private data, which I will flag before starting. I only scrape publicly available data and follow legal limits. Send me the target URL and I will confirm feasibility before you order.
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |

peters1978
Wiederkehrender Kunde

Vereinigte Staaten
Ahmad's work is simply outstanding. For this latest delivery, he not only adapted to a new complex data structure but also proactively built and implemented new, critical safety guardrails into the validation process. The result was a flawless and highly secure dataset. A true professional and a reliable partner.
100 $-200 $
Preis
1 Tag
Dauer
| (1) | ||
| (0) | ||
| (0) | ||
| (0) | ||
| (0) |
peters1978
Wiederkehrender Kunde
Vereinigte Staaten
Ahmad's work is simply outstanding. For this latest delivery, he not only adapted to a new complex data structure but also proactively built and implemented new, critical safety guardrails into the validation process. The result was a flawless and highly secure dataset. A true professional and a reliable partner.
100 $-200 $
Preis
1 Tag
Dauer