Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Azure Data Engineer für Databricks ETL-Pipelines
Willkommen bei meinem Azure Data Engineering Consulting Gig!
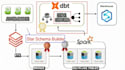
<p suchst du danach, deine Rohdaten in saubere, umsetzbare Erkenntnisse zu verwandeln? Ich spezialisiere mich auf das Entwerfen und Erstellen robuster, skalierbarer Datenpipelines mit dem modernen Azure Data Stack, mit Schwerpunkt auf Azure Databricks und PySpark.Ob du eine architektonische Roadmap, ein einfaches optimiertes Skript oder eine komplette End-to-End ETL/ELT-Pipeline von Grund auf benötigst, ich bin hier, um deine Daten reibungslos und sicher zu bewegen.
Was ich in diesem Gig anbiete:

Automatische Übersetzung
Muss ich meine eigene Azure-Umgebung bereitstellen?
Ja, du musst mir sicheren Zugriff auf dein Azure-Abonnement gewähren (z.B. ein Gastkonto mit bestimmten Ressourcen-Gruppen-Berechtigungen), damit ich die Pipelines direkt in deinem Workspace erstellen, testen und bereitstellen kann.
Was ist die Medallion-Architektur, die du erwähnt hast?
Sie ist ein äußerst effizientes Daten-Design-Muster, das in Databricks verwendet wird. Es organisiert Daten in einem Lakehouse in drei unterschiedliche Schichten: Bronze (rohe, eingelesene Daten), Silber (gereinigte und gefilterte Daten) und Gold (geschäftsbezogene Aggregate, bereit für Analysen und Berichte).
Kannst du einen Fehler in meinem bestehenden PySpark-Code beheben?
Absolut! Das Basic-Paket ist perfekt dafür. Ich kann dein aktuelles Notebook prüfen, den Engpass oder Fehler identifizieren und den optimierten, korrigierten Code liefern.
Müssen wir für die Beratung eine Videoanruf machen?
Überhaupt nicht! Während Fiverr einen Zoom-Link bereitstellt, können wir unsere Kameras ausgeschaltet lassen für einen reinen Audio-Call oder diese Zeit nutzen, um ausführlich per Text zu chatten, während ich deine Architektur und Datenziele überprüfe.
