Kategorien durchsuchen
Entdecken
Fiverr Pro
Deutsch
$
USD
Ich baue AI-Systeme, die deine Geschäftsabläufe steuern
Level 2
Hat hohe Leistungskriterien erfüllt und verfügt über eine nachgewiesene Erfolgsbilanz bei der Erfüllung von Kundenerwartungen.
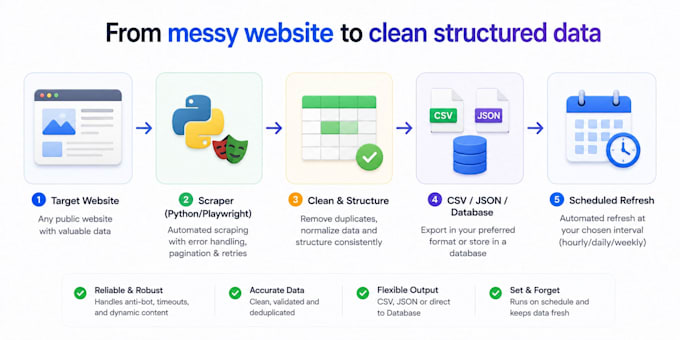
Du brauchst Daten von einer Website, aber das manuelle Kopieren kostet zu viel Zeit? Ich erstelle Python-Scraper und Browser-Automatisierungs-Bots, die saubere, strukturierte Daten automatisch ziehen.
Was ich erstelle:
Tools: Python, Scrapy, BeautifulSoup, Playwright, Selenium, Requests, curl_cffi, Pandas, Proxy-Dienste (Bright Data, ScraperAPI, ZenRows).
Ich liefere einsatzbereiten Code mit klaren Anweisungen, damit du ihn jederzeit selbst wieder ausführen kannst, plus 7 Tage kostenlose Korrekturen.
Schreib mir mit der Ziel-Website und den Feldern, die du brauchst.

Technologie:
Python
•
scrapy
•
Selen
•
Beautiful Soup
•
Dramatiker
Technik:
Automatisiert
Automatische Übersetzung
Ist das legal / konform?
Ich halte mich an die ToS der Website, robots.txt und Datenschutzgesetze. Ich sammle keine sensiblen persönlichen Daten oder umgehe Bezahlschranken. Nur öffentliche/geschäftliche Daten.
Kannst du dynamische Seiten, unendliches Scrollen oder JS-gerenderte Seiten bearbeiten?
Ja, mit Playwright/Selenium/Scrapy, inklusive Pagination, Scrollen, Wartebedingungen und Resilienz gegen Layoutänderungen.
Was brauchen Sie zum Starten?
Website-URL(s), zu extrahierende Felder, Beispielseiten, erwartetes Volumen, Ausgabeformat (CSV/Excel/JSON/Sheets/Datenbank) und ggf. Login-/Test-Zugangsdaten.
Was ist mit Captchas, Rate-Limits oder Blockaden?
Ich nutze rotierende Proxys, User-Agents, Backoff/Wiederholungen und intelligentes Drosseln. Bei starkem Anti-Bot-Schutz schlage ich sichere Alternativen oder Teilabdeckung vor.
Welche Formate können Sie liefern?
CSV, Excel, JSON, Google Sheets oder direkte Übertragung an SQLite/PostgreSQL/MySQL. Ich kann auch eine einfache ETL-fertige Schema bereitstellen.
Füge ich Datenbereinigung und Validierung hinzu?
Ja, Duplikate entfernen, trimmen, Typumwandlungen, Regex-Parsing und Plausibilitätsprüfungen auf Vollständigkeit/Eindeutigkeit, wo anwendbar.
Bekomme ich nur das Daten-Script oder auch das Scraping-Script?
Grundlegende/Standardmäßige Lieferung der Daten. Premium umfasst Python-Code + Setup-Anleitung. Das Script-Ownership wird an dich übertragen.
Kannst du geplantes Scraping / Monitoring einrichten?
Ja, tägliche/wöchentliche Läufe mit E-Mail/Sheets-Updates. Premium kann Docker-Deployment oder einen leichten Cloud-Planer beinhalten.
Kannst du jede Website scrapen, die ich möchte?
Ich kann die meisten öffentlich zugänglichen Websites scrapen. Einige Seiten haben strenge Nutzungsbedingungen oder erfordern Login zu privaten Daten, was ich vor Beginn kennzeichnen werde. Ich scrape nur öffentlich verfügbare Daten und halte mich an rechtliche Grenzen. Schick mir die Ziel-URL und ich bestätige die Machbarkeit, bevor du bestellst.